i深建官方網(wǎng)站怎么做免費(fèi)的網(wǎng)站推廣
【CCF BDCI 2023】多模態(tài)多方對(duì)話場(chǎng)景下的發(fā)言人識(shí)別 Baseline 0.71 NLP 部分
- 概述
- NLP 簡(jiǎn)介
- 文本處理
- 詞嵌入
- 上下文理解
- 文本數(shù)據(jù)加載
- to_device 函數(shù)
- 構(gòu)造
- 數(shù)據(jù)加載
- 樣本數(shù)量 len
- 獲取樣本 getitem
- 分詞
- 構(gòu)造函數(shù)
- 調(diào)用函數(shù)
- 輪次嵌入
- Roberta
- Roberta 創(chuàng)新點(diǎn)
- NSP (Next Sentence Prediction)
- Roberta 構(gòu)造函數(shù)
- Roberta 前向傳播
- 計(jì)算發(fā)言人相似度
- 推理模式 (Inference Mode)
- 訓(xùn)練模式 (Training Mode)
- Deberta
- Deberta 創(chuàng)新點(diǎn)
- Deberta 構(gòu)造函數(shù)
- Deberta 前向傳播
- 訓(xùn)練
- 驗(yàn)證
- 參考文獻(xiàn)
概述
現(xiàn)今技術(shù)日新月異, Artificial Intelligence 的發(fā)展正在迅速的改變我們的生活和工作方式. 尤其是在自然語(yǔ)言處理 (Natural Linguistic Processing) 和計(jì)算機(jī)視覺 (Computer Vision) 等領(lǐng)域.
傳統(tǒng)的多模態(tài)對(duì)話研究主要集中在單一用戶與系統(tǒng)之間的交互, 而忽視了多用戶場(chǎng)景的復(fù)雜性. 視覺信息 (Visual Info) 往往會(huì)被邊緣化, 僅作為維嘉信息而非對(duì)話的核心部分. 在實(shí)際應(yīng)用中, 算法需要 “觀察” 并與多個(gè)用戶的交互, 這些用戶有可能不是當(dāng)前的發(fā)言人.
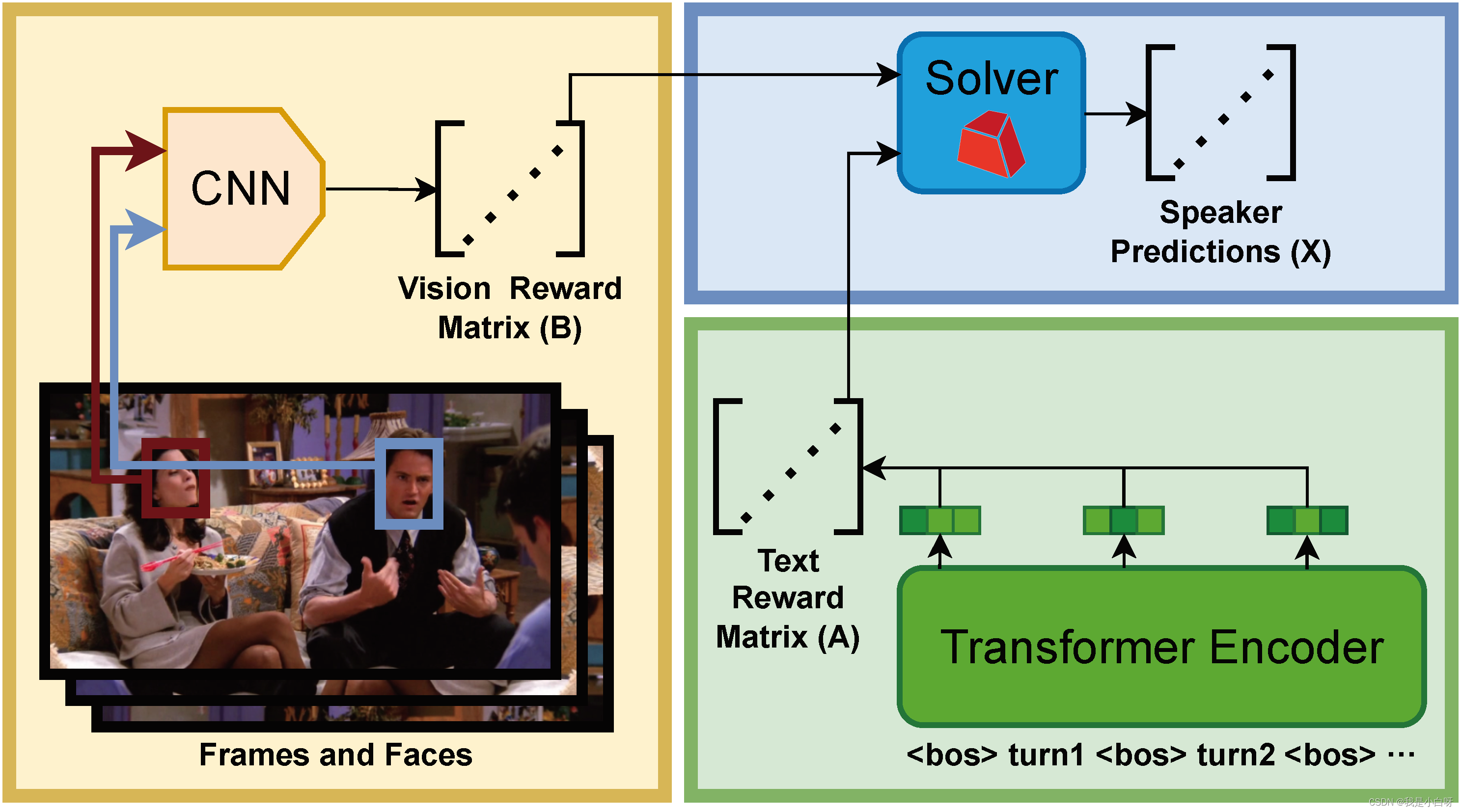
【CCF BDCI 2023】多模態(tài)多方對(duì)話場(chǎng)景下的發(fā)言人識(shí)別, 核心思想是通過多輪連續(xù)對(duì)話的內(nèi)容和每輪對(duì)應(yīng)的幀, 以及對(duì)應(yīng)的人臉 bbox 和 name label, 從每輪對(duì)話中識(shí)別出發(fā)言人 (speaker).
NLP 簡(jiǎn)介
書接上文, 在上一篇博客中小白帶大家詳解了 Baseline 中的 CNN 模型部分. 今天我們來詳解一下 NLP 部分. 包括 Roberta 和 Deberta 模型及其應(yīng)用.

文本處理
文本處理是 NLP 任務(wù)的第一步. 我們需要將原始文本轉(zhuǎn)化成模型可以處理的格式.
步驟包含:
- 清洗 (Cleaning): 去除無用信息, 常見的有標(biāo)點(diǎn)符號(hào), 特殊字符, html, 停用詞等
- 分詞 (Tokenization): 將文本按詞 (Word) 為單位進(jìn)行分割, 并轉(zhuǎn)換為數(shù)字?jǐn)?shù)據(jù).
- 常見單詞, 例如數(shù)據(jù)中的人名:
Rachel對(duì)應(yīng) token id5586Chandler對(duì)應(yīng) token id13814Phoebe對(duì)應(yīng) token id18188- 上述 token id 對(duì)應(yīng) bert 的 vocab 中, roberta 的 vocab 表在服務(wù)器上, 懶得找了
- 特殊字符:
[CLS]: token id101, 表示句子的開始[SEP]: token id102, 表示分隔句子或文本片段[PAD]: token id0, 表示填充 (Padding), 當(dāng)文本為達(dá)到指定長(zhǎng)度時(shí), 例如 512, 會(huì)用[PAD]進(jìn)行填充[MASK]: token id0, 表示填充 (Padding), 當(dāng)文本為達(dá)到指定長(zhǎng)度時(shí), 例如 512, 會(huì)用[PAD]進(jìn)行填充
- 常見單詞, 例如數(shù)據(jù)中的人名:
上述字符在 Bert & Bert-like 模型中扮演著至關(guān)重要的角色, 在不同的任務(wù)重, 這些 Token ID 都是固定的, 例如 Bert 為 30522 個(gè).
FYI: 上面的超鏈接是 jieba 分詞的一個(gè)簡(jiǎn)單示例.
詞嵌入
詞嵌入 (Word Embedding) 是將文本中的詞匯映射到向量空間的過程. 詞向量 (Word Vector) 對(duì)應(yīng)為詞匯的語(yǔ)義信息, 具有相似含義的詞匯在向量空間中距離接近.
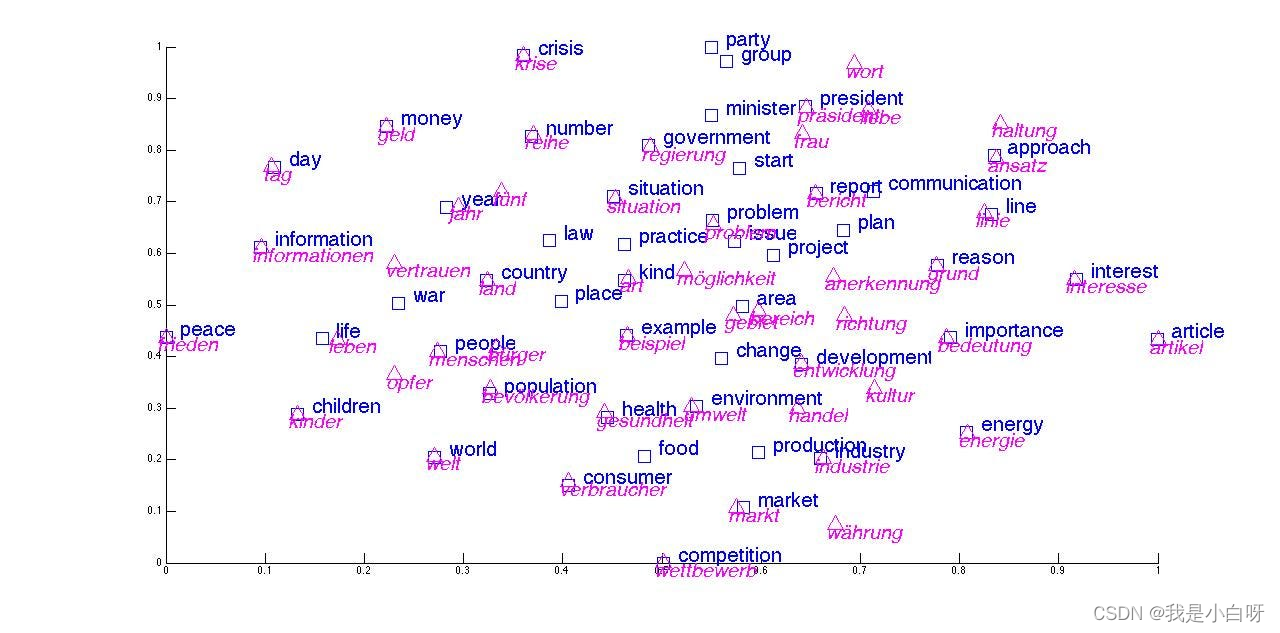
常見的詞嵌入技術(shù)包含:
- Word2Vec: 通過神經(jīng)網(wǎng)絡(luò)模型學(xué)習(xí)詞匯的分布式
- GloVe: 基于全局詞共現(xiàn)統(tǒng)計(jì)信息構(gòu)建詞向量 (Word Vector)
- Bert Embedding: 使用 Bert 模型生成上下文相關(guān)的詞嵌入
FYI: 想要了解詞向量和 Word2Vec 的具體原理, 參考我上面超鏈接的博客.
上下文理解
在多方對(duì)話中, 上下文的理解至關(guān)重要, 包括對(duì)話的語(yǔ)境, 參與者之間的關(guān)系和對(duì)話的流程.
具體技術(shù):
- Transformers 模型, 如 Bert, Roberta, Deberta 等, 通過捕捉長(zhǎng)距離依賴關(guān)系, 理解整個(gè)句子 / 對(duì)話的上下文
- 注意力機(jī)制 (Attention Mechanism): 模型在處理一個(gè)單詞 / 短語(yǔ)時(shí), 考慮到其他相關(guān)部分的信息.
文本數(shù)據(jù)加載
SpeakerIdentificationDataset是用于加載多模態(tài)多方對(duì)話場(chǎng)景下的發(fā)言人識(shí)別任務(wù)中的數(shù)據(jù)的一個(gè)類. 下面小白帶大家來逐行解析.

to_device 函數(shù)
to_device 函數(shù)左右為將數(shù)據(jù)移動(dòng)到指定設(shè)備, 例如 GPU:0.
def to_device(obj, dev):if isinstance(obj, dict):return {k: to_device(v, dev) for k, v in obj.items()}if isinstance(obj, list):return [to_device(v, dev) for v in obj]if isinstance(obj, tuple):return tuple([to_device(v, dev) for v in obj])if isinstance(obj, torch.Tensor):return obj.to(dev)return obj
- 如果傳入對(duì)象為
obj, dict則遞歸的對(duì)這個(gè)字典的每個(gè)值進(jìn)行to_device操作, 將結(jié)果匯總在一個(gè)新的字典上, key 不變, value.to(device) - 如果傳入對(duì)象為
obj, list則遞歸對(duì)列表的每個(gè)元素鏡像``to_device```操作, 將結(jié)果匯總在一個(gè)新的列表上 - 如果傳入對(duì)象為
obj, tuple, 同理, 返回元組 - 如果傳入對(duì)象為
obj, torch.tensor, 將張量移動(dòng)到指定的設(shè)備, 如: CPU->GPU
構(gòu)造
class SpeakerIdentificationDataset:def __init__(self, base_folder, bos_token='<bos>', split='train', dataset='friends', data_aug=False, debug=False):self.base_folder = base_folderself.debug = debugself.dataset = datasetself.split = splitself.bos_token = bos_token
- base_folder: 數(shù)據(jù)集存放路徑
- bos_token: 句子開始時(shí)的特殊字符
- split: 分割 (train, valid, test)
- dataset: 默認(rèn) friends
數(shù)據(jù)加載
if dataset == 'friends':if split == 'test':metadata = json.load(open(os.path.join(base_folder, 'test-metadata.json')))else:if data_aug:metadata = json.load(open(os.path.join(base_folder, 'train-metadata-aug.json')))else:metadata = json.load(open(os.path.join(base_folder, 'train-metadata.json')))self.examples = list()for dialog_data in metadata:# 我們選擇s01作為驗(yàn)證集好了if split == 'valid' and not dialog_data[0]['frame'].startswith('s01'):continueif split == 'train' and dialog_data[0]['frame'].startswith('s01'):continueself.examples.append(dialog_data)
else:if dataset == 'ijcai2019':self.examples = [json.loads(line) for line in open(os.path.join(base_folder, '%s.json' % (split.replace('valid', 'dev'))))]if dataset == 'emnlp2016':self.examples = [json.loads(line) for line in open(os.path.join(base_folder, '10_%s.json' % (split.replace('valid', 'dev'))))]self.examples = [example for example in self.examples if len(example['ctx_spk']) != len(set(example['ctx_spk']))]
和前面的 CNN Dataset 一樣, 還是使用 s01 的 dialog 數(shù)據(jù)做為 valid, 剩下的作為 train.
樣本數(shù)量 len
def __len__(self):return len(self.examples) if not self.debug else 32
- 和 CNN 的 Dataset 一樣, 非 Debug 模式下返回范本數(shù)量, Debug 模型下返回 32
獲取樣本 getitem
def __getitem__(self, index):example = self.examples[index]if self.dataset == 'friends':speakers, contents, frame_names = [i['speaker'] for i in example], [i['content'] for i in example], [i['frame'] for i in example]else:speakers, contents = example['ctx_spk'], example['context']frame_names = ['%d-%d' % (index, i) for i in range(len(speakers))]labels = list()for i, speaker_i in enumerate(speakers):for j, speaker_j in enumerate(speakers):if i != j and speaker_i == speaker_j:labels.append([i, j])input_text = self.bos_token + self.bos_token.join(contents)return input_text, labels, frame_names
- 從數(shù)據(jù)集提取單個(gè) Sample
- 提取發(fā)言人, 對(duì)話內(nèi)容和幀名
- 生成標(biāo)簽, 并標(biāo)記發(fā)言人的位置
- 將對(duì)話內(nèi)容拼接成一個(gè)長(zhǎng)文本, 用于模型輸入
這么說可能大家有點(diǎn)暈, 我來大大家拿 train 的第一個(gè) dialog 演示一下.
Dialog[0] (sample), 5 句話組成:
[{"frame": "s06e07-000377", "speaker": "phoebe", "content": "Yeah, I know because you have all the good words. What do I get? I get \"it\u2019s,\" \"and\" oh I'm sorry, I have \"A.\" Forget it.", "start": 297, "end": 491, "faces": [[[752, 135, 881, 336], "rachel"], [[395, 111, 510, 329], "leslie"]]}, {"frame": "s06e07-000504", "speaker": "rachel", "content": "Phoebe, come on that's silly.", "start": 498, "end": 535, "faces": [[[466, 129, 615, 328], "phoebe"]]}, {"frame": "s06e07-000552", "speaker": "phoebe", "content": "All right, so let's switch.", "start": 535, "end": 569, "faces": [[[426, 120, 577, 320], "phoebe"]]}, {"frame": "s06e07-000629", "speaker": "rachel", "content": "No, I have all of the good words. OK, fine, fine, we can switch.", "start": 569, "end": 689, "faces": [[[420, 125, 559, 328], "phoebe"], [[652, 274, 771, 483], "rachel"]]}, {"frame": "s06e07-000892", "speaker": "phoebe", "content": "Please...wait, how did you do that?", "start": 879, "end": 906, "faces": [[[424, 133, 573, 334], "phoebe"], [[816, 197, 925, 399], "bonnie"]]}]
得到的 input_test:
<bos>Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.<bos>Phoebe, come on that's silly.<bos>All right, so let's switch.<bos>No, I have all of the good words. OK, fine, fine, we can switch.<bos>Please...wait, how did you do that?
得到的 labels:
[[0, 2], [0, 4], [1, 3], [2, 0], [2, 4], [3, 1], [4, 0], [4, 2]]
得到的 frame_names:
['s06e07-000377', 's06e07-000504', 's06e07-000552', 's06e07-000629', 's06e07-000892']
具體說明一下 labels 部分, 上述的 dialog 中的 5 個(gè)發(fā)言人, 依次為:
- Phoebe
- Rachel
- Phoebe
- Rachel
- Phoebe
其中:
- Phoebe 在 1, 3, 5 句子中發(fā)言
- Rachel 在 2, 4 句子中發(fā)言
所以我們可以得到:
- [0, 2]: 1, 3 句子都是同一個(gè)人發(fā)言 (Phoebe)
- [0, 4[: 1, 5 句子都是同一個(gè)人發(fā)言 (Phoebe)
- [1, 3]: 2, 4 句子都素同一個(gè)人發(fā)言 (Rachel)
- [2, 0]: 3, 1 句子都是通一個(gè)人發(fā)言 (Phoebe)
- [2, 4]: 3, 5 句子都是同一個(gè)人發(fā)言 (Phoebe)
- [3, 1]: 4, 2 句子都是同一個(gè)人發(fā)言 (Rachel)
- [4, 0]: 5, 1 句子都是同一個(gè)人發(fā)言 (Phoebe)
- [4, 2]: 5, 3 句子都是同一個(gè)人發(fā)言 (Phoebe)
然后補(bǔ)充一下 input_text 部分:
- 在上面我們提到了一些特殊Token ID,
<bos>就是一個(gè)特殊的 Token ID, 用于表示句子的開始, 幫助模型在生成文本和處理序列時(shí)確定起始點(diǎn) - 在處理對(duì)話時(shí),
<bos>可以用來分隔不同的語(yǔ)句
補(bǔ)充, <sep>和<bos>區(qū)別:
<bos>用于標(biāo)記句子的開始,<sep>用于分隔句子的不同部分

分詞
Collator 類的主要作用是將批次 (Batch) 樣本, tokenize 后轉(zhuǎn)換為模型需要的輸入格式.
構(gòu)造函數(shù)
def __init__(self, tokenizer, max_length=512, temperature=1.0, use_turn_emb=False):self.tokenizer = tokenizerself.max_length = max_lengthself.temperature = temperatureself.use_turn_emb = use_turn_embself.print_debug = True
- tokenizer: 用于文本 tokenize, 例如: RobertaTokenizer
- max_length: 最大長(zhǎng)度限制, 默認(rèn)為 512
- temperature: 模型溫度參數(shù), 默認(rèn)為 1
- use_turn_emb: 是否使用輪次嵌入
調(diào)用函數(shù)
def __call__(self, examples):input_texts = [i[0] for i in examples]labels = [i[1] for i in examples]frame_names = [i[2] for i in examples]model_inputs = self.tokenizer(input_texts, add_special_tokens=False, truncation=True, padding='longest', max_length=self.max_length, return_tensors='pt')model_inputs = dict(model_inputs)
- 獲取 input_texts, labels, frame_names
- tokenize 文本
new_labels = list()
for input_id, label in zip(model_inputs['input_ids'], labels):num_bos_tokens = torch.sum(input_id == self.tokenizer.bos_token_id).item()label = [l for l in label if l[0] < num_bos_tokens and l[1] < num_bos_tokens] # 如果遇到了truncation,將被truncate掉的turn刪除new_labels.append(torch.tensor(label))
model_inputs['labels'] = new_labels
- 創(chuàng)建空列表存放標(biāo)簽
- 遍歷每個(gè)樣本
- 計(jì)算 bos 標(biāo)記數(shù)量
- 更新標(biāo)簽
舉個(gè)例子:
input_text:
Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.[CLS]Phoebe, come on that's silly.[CLS]All right, so let's switch.[CLS]No, I have all of the good words. OK, fine, fine, we can switch.[CLS]Please...wait, how did you do that?
tokenize 后:
[101, 3398, 1010, 1045, 2113, 2138, 2017, 2031, 2035, 1996, 2204, 2616, 1012, 2054, 2079, 1045, 2131, 1029, 1045, 2131, 1000, 2009, 1521, 1055, 1010, 1000, 1000, 1998, 1000, 2821, 1045, 1005, 1049, 3374, 1010, 1045, 2031, 1000, 1037, 1012, 1000, 5293, 2009, 1012, 101, 18188, 1010, 2272, 2006, 2008, 1005, 1055, 10021, 1012, 101, 2035, 2157, 1010, 2061, 2292, 1005, 1055, 6942, 1012, 101, 2053, 1010, 1045, 2031, 2035, 1997, 1996, 2204, 2616, 1012, 7929, 1010, 2986, 1010, 2986, 1010, 2057, 2064, 6942, 1012, 101, 3531, 1012, 1012, 1012, 3524, 1010, 2129, 2106, 2017, 2079, 2008, 1029, 102]
注: 這邊我用的是 Bert [CLS], 等同于<bos>
new_labels:
[[0, 2], [0, 4], [1, 3], [2, 0], [2, 4], [3, 1], [4, 0], [4, 2]]
因?yàn)樯厦娴?5 個(gè)句子加起來并沒有達(dá)到 512 個(gè)詞, 所以 label 并沒有進(jìn)行刪減. 如果 比如<bos只有4 個(gè), 即最后一個(gè)句子被裁剪 (truncation) 了, 此時(shí)就要去掉所有包括句子 5 的 label.
假設(shè)上面句子只有三句半, new_labels 為:
[[0, 2], [1, 3], [2, 0], [3, 1]]
輪次嵌入
if self.use_turn_emb:model_inputs['token_type_ids'] = torch.cumsum(model_inputs['input_ids'] == self.tokenizer.bos_token_id, dim=1)
model_inputs['frame_names'] = frame_names
model_inputs['temperature'] = self.temperature
計(jì)算輪次嵌入: 使用torch.cumsum函數(shù)計(jì)算累積和. model_inputs['input_ids'] == self.tokenizer.bos_token_id創(chuàng)建了一個(gè)布爾張亮, 每個(gè)句子開始<bos>標(biāo)記的位置為 True, 其他位置為 False
對(duì)話:
Yeah, I know because you have all the good words. What do I get? I get "it’s," "and" oh I'm sorry, I have "A." Forget it.
[CLS]
Phoebe, come on that's silly.
[CLS]
All right, so let's switch.
[CLS]
No, I have all of the good words. OK, fine, fine, we can switch.
[CLS]
Please...wait, how did you do that?
輪次嵌入前的 token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
輪次嵌入后的 token_type_ids:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5]
類似:
1: ["Yeah", ",", "I", "know", "because", "you", "have", "all", "the", "good", "words", ".", "What", "do", "I", "get", "?", "I", "get", "it’s", ",", "and", "oh", "I", "'m", "sorry", ",", "I", "have", "A", ".", "Forget", "it", "."]
2: ["Phoebe", ",", "come", "on", "that", "'s", "silly", "."]
3: ["All", "right", ",", "so", "let", "'s", "switch", "."]
4: ["No", ",", "I", "have", "all", "of", "the", "good", "words", ".", "OK", ",", "fine", ",", "fine", ",", "we", "can", "switch", "."]
5: ["Please", "...", "wait", ",", "how", "did", "you", "do", "that", "?"]
輪次嵌入的作用:
輪次嵌入對(duì)處理對(duì)話和交互文本時(shí)至關(guān)重要. 輪次嵌入為模型提供了關(guān)于每個(gè)單詞屬于哪個(gè)對(duì)話, 對(duì)于模型理解對(duì)話結(jié)構(gòu)和上下文非常重要.
在上面的例子中, 我們有 5 句話組成的 dialog, 經(jīng)過輪次嵌入, 第一句的單詞會(huì)被標(biāo)記為 1, 第二句為 2, 第三句為 3, 第四句為 4, 第五句為 5. 通過 1, 2, 3, 4, 5 的標(biāo)記, 可以幫助模型區(qū)分不同句子的語(yǔ)境, 以更好的處理每個(gè)對(duì)話.
Roberta
Roberta (Robustly Optimized BERT Approach) 是一種基于 BERT (Bidirectional Encoder Representations from Transformers) 的 NLP 模型.
Roberta 創(chuàng)新點(diǎn)
Roberta 在 Bert 的基礎(chǔ)上創(chuàng)新了訓(xùn)練過程和數(shù)據(jù)處理方式. First, Roberta 使用的語(yǔ)料庫(kù)更大, 數(shù)據(jù)更難多, 模型更更好的理解和處理復(fù)雜的語(yǔ)言模式. Second, Roberta 取消了 Bert 中的下句預(yù)測(cè) (Next Sentence Prediction). Third, Roberta 對(duì)輸入數(shù)據(jù)的處理方式也進(jìn)行了優(yōu)化, 具體表現(xiàn)為更長(zhǎng)序列進(jìn)行的訓(xùn)練, 因此 Roberta 的長(zhǎng)文本處理能力也更為優(yōu)秀.
NSP (Next Sentence Prediction)
- NSP (Next Sentence Prediction) 目的是改善模型 (Bert) 對(duì)句子關(guān)系的理解, 特別是在理解段落或文檔中句子之間的關(guān)系方面
- NSP 任務(wù)重, 模型唄訓(xùn)練來預(yù)測(cè)兩個(gè)句子是否在原始文本中相鄰. 舉個(gè)栗子: A & B 倆句子, 模型需要判斷 B 是否是緊跟在 A 后面的下一句. 在 Training 過沖中, Half time B 確實(shí)是 A 的下一句, 另一半時(shí)間 B 則是從語(yǔ)料庫(kù)中隨機(jī)選取的與 A 無關(guān)的句子. NSP 就是基于這些句子判斷他們是否是連續(xù)的
- 句子 A: “我是小白呀今年才 18 歲”
- 句子 B: “真年輕”
- NSP: 連續(xù), B 是對(duì) A 的回應(yīng) (年齡), 表達(dá)了作者 “我” 十分年輕
- 句子 A: “意大利面要拌”
- 句子 B: “42 號(hào)混凝土”
- NSP: 不連續(xù), B 和 A 內(nèi)容完全無關(guān)
- NSP 對(duì)諸如系統(tǒng)問答, 文本摘要等任務(wù)十分重要, 但是 Roberta 發(fā)現(xiàn)去除也一樣, 因?yàn)?Bert 底層的雙向結(jié)構(gòu)十分強(qiáng)大. 后續(xù)的新模型, Roberta, Xlnet, Deberta 都去除了 NSP
Roberta 構(gòu)造函數(shù)
構(gòu)造函數(shù):
def __init__(self, config):super().__init__(config)self.bos_token_id = config.bos_token_idself.loss_fct = CrossEntropyLoss(reduction='none')...以下省略
- bos_token_id: 句子起始標(biāo)記
- los_fct: 損失函數(shù), 這邊為交叉熵?fù)p失 (CrossEntropyLoss)
Roberta 前向傳播
def forward(...):...以上省略outputs = self.roberta(...)last_hidden_state = outputs[0]...以下省略
- last_hidden_state: 獲取 Roberta 輸出的隱層狀態(tài)
計(jì)算發(fā)言人相似度
這邊的計(jì)算發(fā)言人相似度分為兩個(gè)模式, 分別為推理模式 (Inference Mode) 和訓(xùn)練模式 (Training Mode).
推理模式 (Inference Mode)
在 labels == None 的時(shí)候, 模型進(jìn)行推理模式 (Inference Mode). 在這種模式下, 模型的主要任務(wù)是計(jì)算并返回每個(gè)句子的隱層狀態(tài)和相似度得分, 而不是進(jìn)行模型的訓(xùn)練. 用于 valid 和 test.
if labels is None:# inference modeselected_hidden_state_list, logits_list = list(), list()for i, (hidden_state, input_id) in enumerate(zip(last_hidden_state, input_ids)):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)logits = torch.matmul(selected_hidden_state, selected_hidden_state.t())logits += torch.eye(len(logits), device=logits.device) * -100000.0 # set elements on the diag to -infelse:num_sents, hidden_size = selected_hidden_state.size()# concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*4, device=selected_hidden_state.device)concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*3, device=selected_hidden_state.device)concatenated_hidden_state[:, :, :hidden_size] = selected_hidden_state.unsqueeze(1)concatenated_hidden_state[:, :, hidden_size:hidden_size*2] = selected_hidden_state.unsqueeze(0)concatenated_hidden_state[:, :, hidden_size*2:hidden_size*3] = torch.abs(selected_hidden_state.unsqueeze(0) - selected_hidden_state.unsqueeze(1))# concatenated_hidden_state[:, :, hidden_size*3:hidden_size*4] = selected_hidden_state.unsqueeze(0) + selected_hidden_state.unsqueeze(1)logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze() # 但要注意,這里的logits就不能保證是在0-1之間了。需要過sigmoid才能應(yīng)用在之后的任務(wù)中selected_hidden_state_list.append(selected_hidden_state) # 不同對(duì)話的輪數(shù)可能不一樣,所以結(jié)果可能不能stack起來。logits_list.append(logits)
推理模式下的步驟:
- 提取隱層狀態(tài) (Hidden State): 從前面的 Roberta 模型提取每個(gè)句子的 hidden state
- 計(jì)算相似度得分: 線性相似度頭
sim_head來計(jì)算不同句子之間的相似度得分. 這些得分表示句子間的相似性, 用于判斷是否是同一個(gè)發(fā)言人 (Speaker)
訓(xùn)練模式 (Training Mode)
當(dāng) label != None, 模型進(jìn)行訓(xùn)練模式 (Training Mode). 在這種模式下, 模型的主要任務(wù)是通過損失函數(shù)來優(yōu)化模型.
else:# training modeselected_hidden_state_list = list()batch_size = len(labels)for hidden_state, input_id in zip(last_hidden_state, input_ids):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)selected_hidden_state_list.append(selected_hidden_state)losses, logits_list = list(), list()for i, (selected_hidden_state, label) in enumerate(zip(selected_hidden_state_list, labels)):if not self.linear_sim:other_selected_hidden_states = torch.cat([selected_hidden_state_list[j] for j in range(batch_size) if j != i])all_selected_hidden_states = torch.cat([selected_hidden_state, other_selected_hidden_states])logits = torch.matmul(selected_hidden_state, all_selected_hidden_states.t())logits += torch.cat([torch.eye(len(logits), device=logits.device) * -100000.0, torch.zeros(len(logits), len(other_selected_hidden_states), device=logits.device)], dim=-1)if label.numel():losses.append(self.loss_fct(logits[label[:, 0]] / temperature, label[:, 1]))else:num_sents, hidden_size = selected_hidden_state.size()# concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*4, device=selected_hidden_state.device)concatenated_hidden_state = torch.zeros(num_sents, num_sents, hidden_size*3, device=selected_hidden_state.device)concatenated_hidden_state[:, :, :hidden_size] = selected_hidden_state.unsqueeze(1)concatenated_hidden_state[:, :, hidden_size:hidden_size*2] = selected_hidden_state.unsqueeze(0)concatenated_hidden_state[:, :, hidden_size*2:hidden_size*3] = torch.abs(selected_hidden_state.unsqueeze(0) - selected_hidden_state.unsqueeze(1))# concatenated_hidden_state[:, :, hidden_size*3:hidden_size*4] = selected_hidden_state.unsqueeze(0) + selected_hidden_state.unsqueeze(1)logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze() # 但要注意,這里的logits就不能保證是在0-1之間了。需要過sigmoid才能應(yīng)用在之后的任務(wù)中# 使用mse作為loss。loss包括兩部分,一個(gè)是和gold的,一個(gè)是和自己的轉(zhuǎn)置的logits = nn.Sigmoid()(logits)real_labels = torch.zeros_like(logits)if label.numel():real_labels[label[:, 0], label[:, 1]] = 1real_labels += torch.eye(len(logits), device=logits.device)loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1))losses.append(loss)logits_list.append(logits)loss = torch.mean(torch.stack(losses))return MaskedLMOutput(loss=loss, logits=logits_list, hidden_states=selected_hidden_state_list)
訓(xùn)練模式下的具體步驟:
- 提取隱層狀態(tài) (Hidden State): 從前面的 Roberta 模型提取每個(gè)句子的 hidden state
- 計(jì)算相似度得分: 使用模型輸出的相似度 logits
- 計(jì)算損失函數(shù): 通過計(jì)算 logits 和 real_label 之間的差異
- 優(yōu)化模型: 根據(jù) loss 進(jìn)行梯度下降, 反向傳播 (Backpropagation)
以防大家沒看懂, 下面我們來逐行解析:
提取隱層狀態(tài):
selected_hidden_state_list = list()
for hidden_state, input_id in zip(last_hidden_state, input_ids):indices = input_id == self.bos_token_idselected_hidden_state = hidden_state[indices]if not self.linear_sim:selected_hidden_state = F.normalize(selected_hidden_state, p=2, dim=-1)selected_hidden_state_list.append(selected_hidden_state)
- 通過
<bos>標(biāo)注每個(gè)句子開始, 并選取對(duì)應(yīng)句子的隱藏狀態(tài)
線性層計(jì)算相似度:
losses, logits_list = list(), list()
for i, (selected_hidden_state, label) in enumerate(zip(selected_hidden_state_list, labels)):# 根據(jù)配置選擇相似度計(jì)算方法if not self.linear_sim:# 非線性相似度計(jì)算...else:# 線性相似度計(jì)算concatenated_hidden_state = ...logits = self.sim_head(self.dropout(concatenated_hidden_state)).squeeze()logits = nn.Sigmoid()(logits)real_labels = torch.zeros_like(logits)if label.numel():real_labels[label[:, 0], label[:, 1]] = 1real_labels += torch.eye(len(logits), device=logits.device)loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1))losses.append(loss)logits_list.append(logits)
- 在線相似度計(jì)算中, 使用
sim_head來計(jì)算句子間的相似度得分 - 計(jì)算損失函數(shù). 損失函數(shù)的計(jì)算分為兩部分:
- 第一部分: y_predict 和 y_true 之間的差異. 具體為
loss_similarity = nn.MSELoss()(real_labels, logits) - 第二部分: 計(jì)算矩陣的對(duì)稱性. 因?yàn)榫渥拥南嗨贫仁请p向的 (A -> B & B -> A 的相似度應(yīng)該相同) 所以這邊有一個(gè)對(duì)稱項(xiàng)來確保 loss 矩陣的對(duì)稱性:
loss_symmetry = nn.MSELoss()(logits, logits.transpose(0, 1)) - 相加:
loss = loss_similarity + loss_symmetry
- 第一部分: y_predict 和 y_true 之間的差異. 具體為
注: Baseline 代碼為loss = nn.MSELoss()(real_labels, logits) + nn.MSELoss()(logits, logits.transpose(0, 1)), 我就是拆開了而已, 勿噴.
Deberta
Deberta (Decoding-enhanced Bert with Disentangled Attention) 也是一種 NLP 模型. Deberta 在 Bert (Bidirectional Encoder Representations from Transformers) 和 Roberta (Robustly Optimized Bert Approach) 的基礎(chǔ)上進(jìn)行了創(chuàng)新和改進(jìn), 主要為獨(dú)特的注意力機(jī)制 (Attention) 和編碼策略, 使得 Deberta 在 NLP 任務(wù)重表現(xiàn)出色.
Deberta 創(chuàng)新點(diǎn)
Deberta 的主要?jiǎng)?chuàng)新點(diǎn):
- 解耦注意力機(jī)制 (Disentangled Attention Mechanism): Deberta 的解耦注意力機(jī)制, 將內(nèi)容和位置信息分開處理. 在傳統(tǒng) Bert 和 Roberta 模型重, 注意力機(jī)制 (Attention) 同時(shí)考慮了內(nèi)容和位置信息. Deberta 將這兩種信息分離, 允許模型更靈活的學(xué)習(xí)單詞之間的以來關(guān)系
- 增強(qiáng)的位置編碼 (Positional Encoding). Deberta 的位置編碼方案不僅考慮了單詞之間相對(duì)位置, 還考慮他們?cè)谛蛄兄械慕^對(duì)位置. 這種雙重位置編碼使得 Deberta 能夠更準(zhǔn)確的捕捉文本中的結(jié)構(gòu)信息
- 動(dòng)態(tài)卷積 (Dynamic Convolution): 相較于 CNN 中的標(biāo)準(zhǔn)卷積, 動(dòng)態(tài)卷積具有更高的靈活性和適應(yīng)性:
- 權(quán)重的動(dòng)態(tài)生成: 標(biāo)準(zhǔn)卷積中, 權(quán)重 (W) 在整個(gè)測(cè)試集上是固定不變的, 而動(dòng)態(tài)卷積是動(dòng)態(tài)生成的, 根據(jù)輸入數(shù)據(jù)不同而改變
- 適應(yīng)性強(qiáng): 由于卷積核的權(quán)重是針對(duì)每個(gè)輸入樣本動(dòng)態(tài)生成的, 能更好的適應(yīng)不同的語(yǔ)言模式和上下文環(huán)境
- 捕獲局部依賴: 動(dòng)態(tài)卷積特別刪除捕捉文本中的局部依賴關(guān)系, 如短語(yǔ)或局部語(yǔ)義結(jié)構(gòu), 對(duì)于理解復(fù)雜的語(yǔ)言表達(dá)至關(guān)重要
Deberta 構(gòu)造函數(shù)
Deberta 構(gòu)造函數(shù):
def __init__(self, config):super().__init__(config)self.bos_token_id = config.bos_token_idself.loss_fct = CrossEntropyLoss(reduction='none')
Deberta 前向傳播
同 Roberta
訓(xùn)練
同 cnn
驗(yàn)證
同 cnn
參考文獻(xiàn)
比賽鏈接
Baseline 完整代碼