家居裝修公司百度關(guān)鍵詞優(yōu)化大師
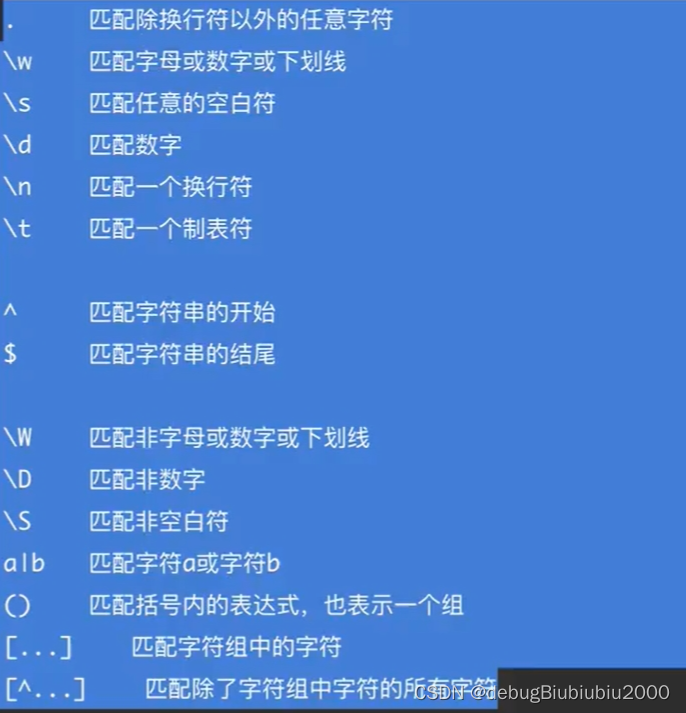
正則表達(dá)式基礎(chǔ)
元字符
B站教學(xué)視頻:?正則表達(dá)式元字符基本使用
量詞

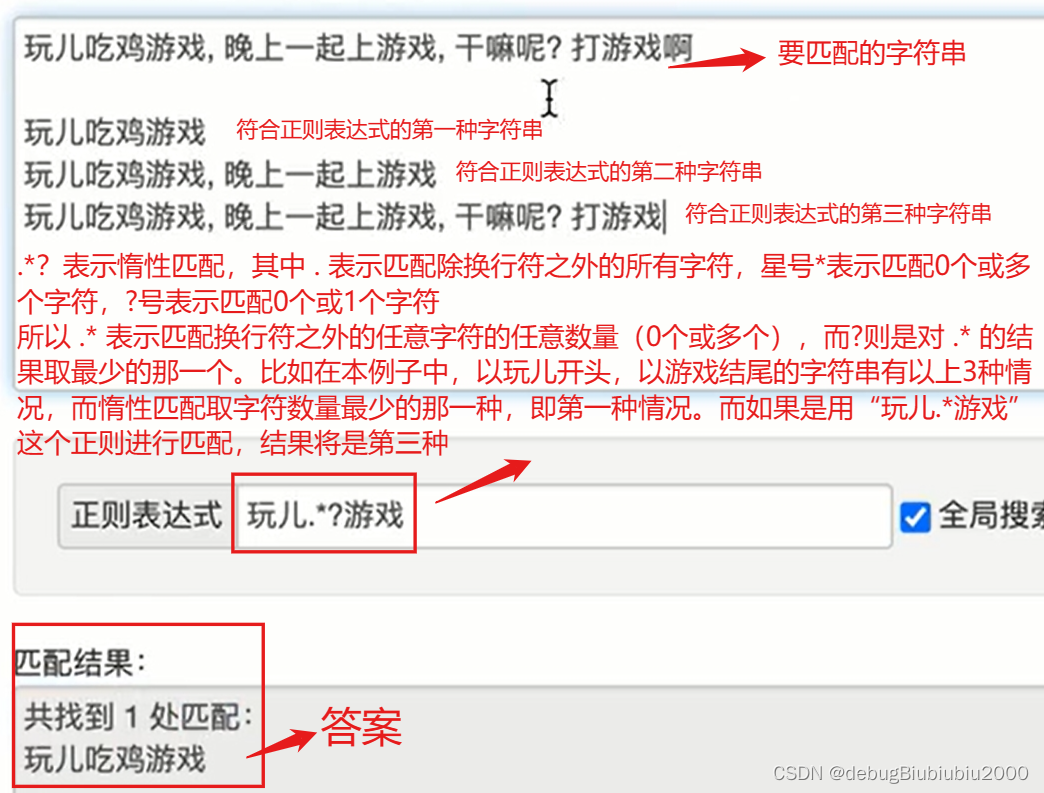
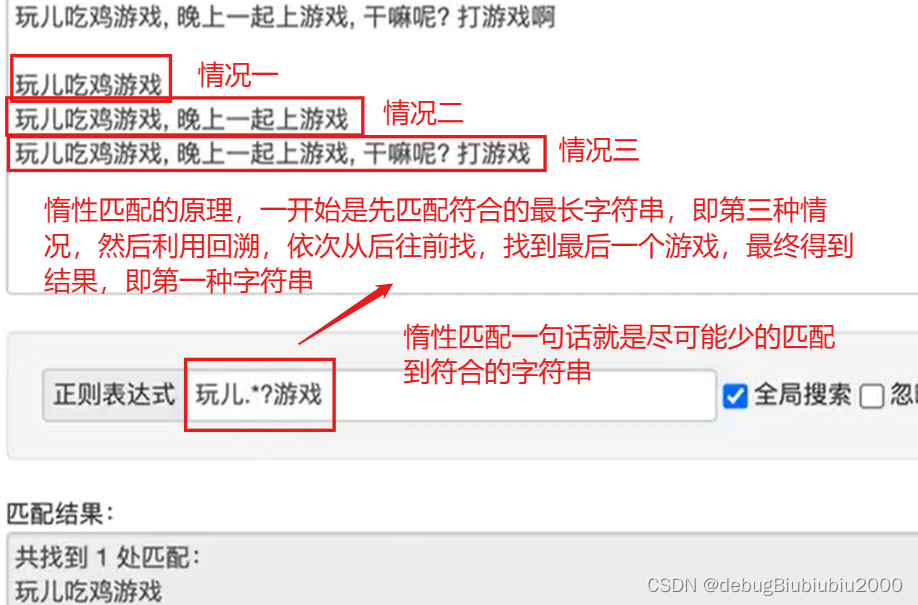
貪婪匹配和惰性匹配
惰性匹配如下兩張圖,而 .* 就表示貪婪匹配,即盡可能多的匹配到符合的字符串,如果使用貪婪匹配,那么結(jié)果就是圖中的情況三
python中re模塊
re模塊的常用方法
import re# findall(正則表達(dá)式, 待匹配的字符串) -> 符合正則表達(dá)式的內(nèi)容(以列表的形式返回)
# 含義:匹配字符串中所有符合正則表達(dá)式的內(nèi)容(以列表的形式返回)
res_findall = re.findall(r"\d+", "中國移動(dòng):10086,中國聯(lián)通:10010")
print(res_findall) # ['10086', '10010']# re.finditer(正則表達(dá)式, 待匹配的字符串) -> 符合正則表達(dá)式的內(nèi)容(以迭代器的形式返回)
# 含義:匹配字符串中所有符合正則表達(dá)式的內(nèi)容(以迭代器的形式返回)
res_finditer = re.finditer(r"\d+", "中國移動(dòng):10086,中國聯(lián)通:10010")
print(res_finditer) # <callable_iterator object at 0x000001CB2875B340>
for item in res_finditer:"""下面兩行輸出語句的輸出結(jié)果如下:<re.Match object; span=(5, 10), match='10086'>10086<re.Match object; span=(16, 21), match='10010'>10010item 中還有其他的方法,如item.start()/item.end()分別表示匹配到的字符串在原字符串中的起始索引和結(jié)束索引"""print(item) # 得到match對(duì)象print(item.group()) # 得到匹配的字符串# re.search(正則表達(dá)式, 待匹配的字符串) -> 符合正則表達(dá)式的內(nèi)容(返回match對(duì)象)
# 含義:匹配字符串中第一個(gè)匹配到的符合正則表達(dá)式的內(nèi)容(返回match對(duì)象)
res_search = re.search(r"\d+", "中國移動(dòng):10086,中國聯(lián)通:10010")
print(res_search) # <re.Match object; span=(5, 10), match='10086'>
print(res_search.group()) # 10086# 上述三種方法都是全文匹配,而match是從頭開始匹配
# re.match(正則表達(dá)式, 待匹配的字符串) -> 符合正則表達(dá)式的第一個(gè)字符串內(nèi)容(返回match對(duì)象)
# 含義:從待匹配的字符串的第一個(gè)字符開始匹配,將匹配到的第一個(gè)結(jié)果返回,返回的是match對(duì)象
res_match = re.match(r"\d+", "中國移動(dòng):10086,中國聯(lián)通:10010")
print(res_match) # None,字符串開頭不是數(shù)字,所以等于匹配不成功,結(jié)果為空
# print(res_match.group()) # 報(bào)錯(cuò)
res_match = re.match(r"\d+", "10086,中國聯(lián)通:10010")
print(res_match) # <re.Match object; span=(0, 5), match='10086'>
print(res_match.group()) # 10086# 預(yù)加載
# 應(yīng)用場景:在爬蟲中,想要從網(wǎng)頁中匹配到想要的內(nèi)容,匹配的正則表達(dá)式可能會(huì)很復(fù)雜,
# 而又多次的使用到該正則表達(dá)式,則可以預(yù)加載正則表達(dá)式
# 如下,好處就是該正則可以反復(fù)使用
obj = re.compile(r"\d+")
res1 = obj.findall("中國移動(dòng):10086,中國聯(lián)通:10010")
res2 = obj.finditer("中國移動(dòng):10086,中國聯(lián)通:10010")
res3 = obj.search("中國移動(dòng):10086,中國聯(lián)通:10010")
res4 = obj.match("中國移動(dòng):10086,中國聯(lián)通:10010")分組匹配
s = """<div class="jay">周杰倫</div><div class="jj">林俊杰</div>
"""
# (?P<name>.*?) 分組匹配(P為大寫),相當(dāng)于把括號(hào)中的.*?匹配到的內(nèi)容給變量name
# 然后通過item.group('name')獲取到name的值
# 只要把想要單獨(dú)獲取的內(nèi)容按以上形式:(?P<xxx>正則表達(dá)式) 即可獲取
# re.S 的作用就是讓 . 也可以匹配到換行符
# flags 是re模塊中compile、match、findall等方法的一個(gè)參數(shù),具體用法可以百度
obj = re.compile(r'<div class=".*?">(?P<name>.*?)</div>', re.S)
res = obj.finditer(s)
print(res) # <callable_iterator object at 0x0000020F2E89AEC0>
for item in res:"""輸出結(jié)果如下:<re.Match object; span=(5, 31), match='<div class="jay">周杰倫</div>'><div class="jay">周杰倫</div>周杰倫<re.Match object; span=(36, 61), match='<div class="jj">林俊杰</div>'><div class="jj">林俊杰</div>林俊杰"""print(item) # <re.Match object; span=(5, 31), match='<div class="jay">周杰倫</div>'>print(item.group()) # <div class="jay">周杰倫</div>print(item.group('name')) # 周杰倫注:關(guān)于re模塊方法中的flags參數(shù)作用,可以百度一下
案例——豆瓣top250(re解析版)
B站視頻教程:爬取豆瓣top250電影
import requests
import re
import csvurl = "https://movie.douban.com/top250"
headers = {"User-Agent": "xxx(寫上自己電腦的)"
}
resp = requests.get(url, headers=headers)
# print(resp.text) # 沒加headers之前結(jié)果為空,說明網(wǎng)站有一些反扒機(jī)制
pattern = (r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'r'導(dǎo)演: (?P<director>.*?) .*?主演: (?P<performer>.*?)...<br>.*?'r'<span class="rating_num" property="v:average">(?P<score>\d.\d)</span>')obj = re.compile(pattern, re.S)
res = obj.finditer(resp.text)
# 把獲取到的數(shù)據(jù)存入CSV文件,方便以后對(duì)數(shù)據(jù)進(jìn)行操作
# 關(guān)于CSV文件,請(qǐng)百度
f = open('data.csv', mode='w', encoding='utf-8')
csv_writer = csv.writer(f) # 表示向文件寫入數(shù)據(jù)
for i in res:# print(i.group('name'))# print(i.group('director'))# print(i.group('performer'))# print(i.group('score').strip())dic = i.groupdict() # 將數(shù)據(jù)以字典形式返回# print(dic)# 將字典的值按行寫入文件,文件中的每一行就是一部電影的信息# csv文件中,每一行數(shù)據(jù)以逗號(hào)分隔每個(gè)值csv_writer.writerow(dic.values())
f.close()
resp.close()
print("數(shù)據(jù)解析完成!")
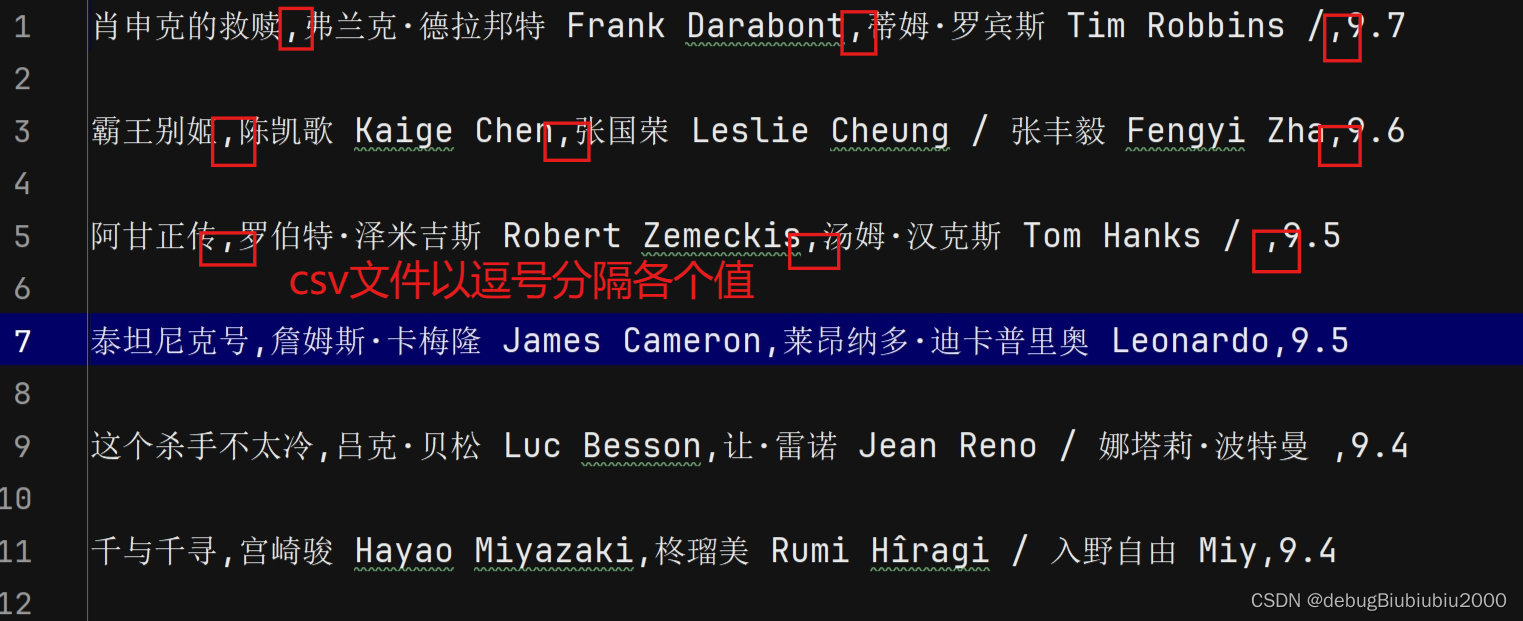
部分csv文件內(nèi)容如下: